.png)


Report summary
This report documents six bias patterns detected in ChatGPT across 20 days of empirical visibility data, covering 8 B2B SaaS brands, 8 product categories, and 4 major AI engines: ChatGPT, Perplexity, Google AI Overviews, and Google AI Mode. The goal is to identify where ChatGPT's recommendations diverge from market reality, and to understand the mechanisms behind those divergences.
What the data shows is a system shaped less by present-day market conditions than by the structure of its training corpus: a disproportionate reliance on Wikipedia, a citation pool concentrated in a small number of high-authority domains, a consistent over-representation of Microsoft and OpenAI-adjacent products, and a near-complete dependence on third-party review content over owned brand assets.
All six patterns hold consistently across categories, brands, and time periods.
Empirical data (useomnia.com)
Study methodology
- Monitoring period: March 22- 31 2026 (20 days)
- Engines analysed: OpenAI (ChatGPT), Perplexity, Google AI Overviews, Google AI Mode
- Total queries per prompt: 80 (4 engines × 20 days)
- Active prompts per brand: 10 (non-branded + branded)
- Total prompt queries: 6400
- Brands analysed: Attio.com, Claude.ai, Cursor.com, Linear.app, Notion.com, Stripe.com, Vercel.com, Supabase.com
- Categories covered: CRM, AI Assistant, IDE/Coding, Project Management, Workspace, Payments, Frontend/Deploy, Backend/Database.
Patterns detected in ChatGPT
Pattern 1: Selective self-promotion
ChatGPT systematically self-promotes when asked about AI assistants, but does not appear among the dominant sources in any other category. The self-promotion is selective, not universal.
Evidence:
- OpenAI appears in responses about Claude with 14.69% SOV, the most mentioned competitor in that category
- OpenAI has 71,64% visibility in the AI Assistant category, ahead of Claude (43,52%)
- OpenAI is the competitors more recurrent citation, with a 2.09% overall. Claude represents a 0%.
Brand implication: Claude has a structural disadvantage, the engine evaluating it is its primary competitor. For competitive analysis in the AI Assistant category, ChatGPT data must be interpreted with this distortion in mind.
Pattern 2: Over-representation of the Microsoft/GitHub ecosystem in coding tools
In the developer tools category, ChatGPT cites and recommends the Microsoft/GitHub ecosystem 2.1x more frequently than Cursor, the category leader by its own SOV.
Evidence:
- Cursor SOV on ChatGPT: 12.00% (rank #2 in its category), rather than Github, who shows a 15.47% (rank #1).
- GitHub + Microsoft combined: 23.56% SOV, 2x more than Cursor
- Codex (OpenAI) represents a 9.17% SOV. Together with GitHub and Microsoft, the three companies account for roughly 31.25% of the total
Mechanism: Microsoft invested $10B in OpenAI and all stateless API access to OpenAI flows contractually through Azure. This relationship creates a presence asymmetry in training data and possibly in the model's relevance criteria.
Brand implication: Cursor's SOV in ChatGPT understates its real market position. For brands in categories with OpenAI investor partners, Google AI Mode and Perplexity are more neutral references.
Pattern 3: Neutrality in categories with no conflict of interest
In 5 of the 8 categories analysed, ChatGPT shows equitable behaviour: brands appear in proportion to their apparently real market authority, with no over-representation of OpenAI commercial partners or investors.
Evidence:
- CRM: HubSpot, Salesforce, Zoho and Pipedrive dominate by real brand authority. Attio appears in proportion to its notoriety
- Payments: Stripe leads (19,50% SOV), PayPal, Paddle, Lemon Squeezy appear in a balanced way
- Project Management: Jira (Atlassian) dominates (13.54% SOV), Linear appears as the forth alternative, after Asana and ClickUp
- Workspace: Notion leads (16.33% SOV). Obsidian, Evernote, Microsoft appear proportionally
- Frontend/Deploy: Vercel leads (10.50% SOV). Netlify, AWS Amplify, GitHub appear without distortion
Brand implication: For brands in neutral categories, SOV in ChatGPT is a reliable indicator of real positioning.
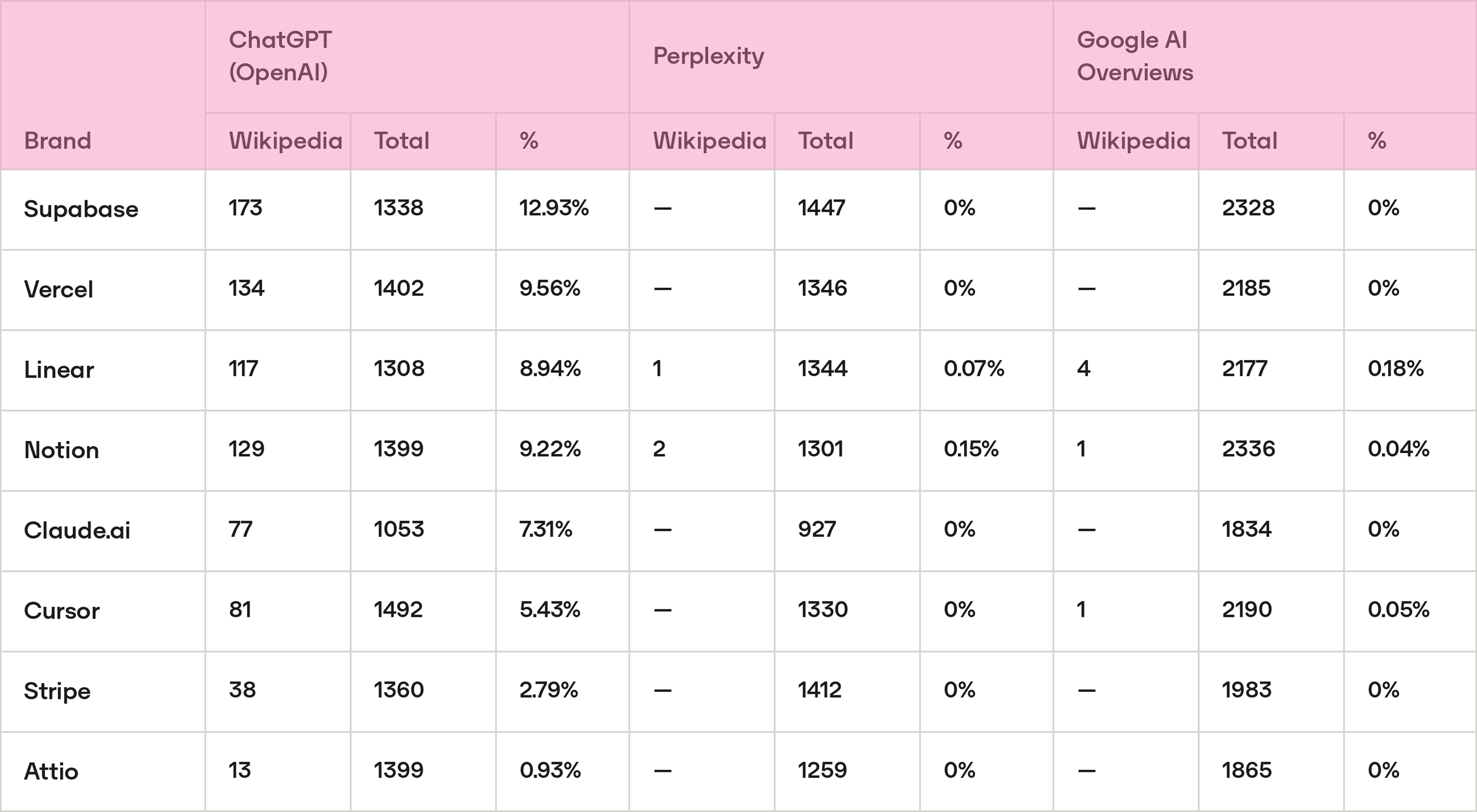
Pattern 4: Wikipedia as an authority bias amplifier
ChatGPT uses Wikipedia as a primary source disproportionately. Brands with more extensive and recent Wikipedia articles receive more citations in ChatGPT, regardless of their current market relevance.
Evidence:
- Wikipedia accounts for 642 citations across the 8 brands studied on ChatGPT, representing the 7.09% of all ChatGPT citations recorded, making it the single most cited domain across every category analysed.
- The gap between engines is big. Google AI Overviews cited Wikipedia just 6 times in total across all 8 brands; Perplexity cited it just 3 times. ChatGPT, by contrast, cited it 762 times, more than a hundred times as often as either of the other two engines combined.
- The most extreme case is Supabase: where Wikipedia accounts for 12.93% of all ChatGPT citations about the brand, with 173 citations, which is the highest ratio in the study. Supabase (founded 2020, roughly 4 years of web presence) competes directly against Firebase (acquired by Google in 2014, with 13+ years of accumulated web presence). ChatGPT's citation patterns reflect that historical corpus, not the current state of the open-source market.
Mechanism: The underlying mechanism is architectural. ChatGPT was trained on Wikipedia dumps as a high-quality, structured knowledge source, and that training-time weighting persists in citation behaviour at inference time. Wikipedia functions as a proxy authority signal, regardless of whether a given article accurately reflects the current competitive landscape.
Brand implication: Wikipedia presence is currently the highest-ROI lever for improving visibility in ChatGPT based on the data of this study. For young brands and startups, product quality alone does not close the historical authority gap in the short term, the model's prior is already set, and it will not be revised by recent third-party content at the same rate as a well-maintained Wikipedia article would.
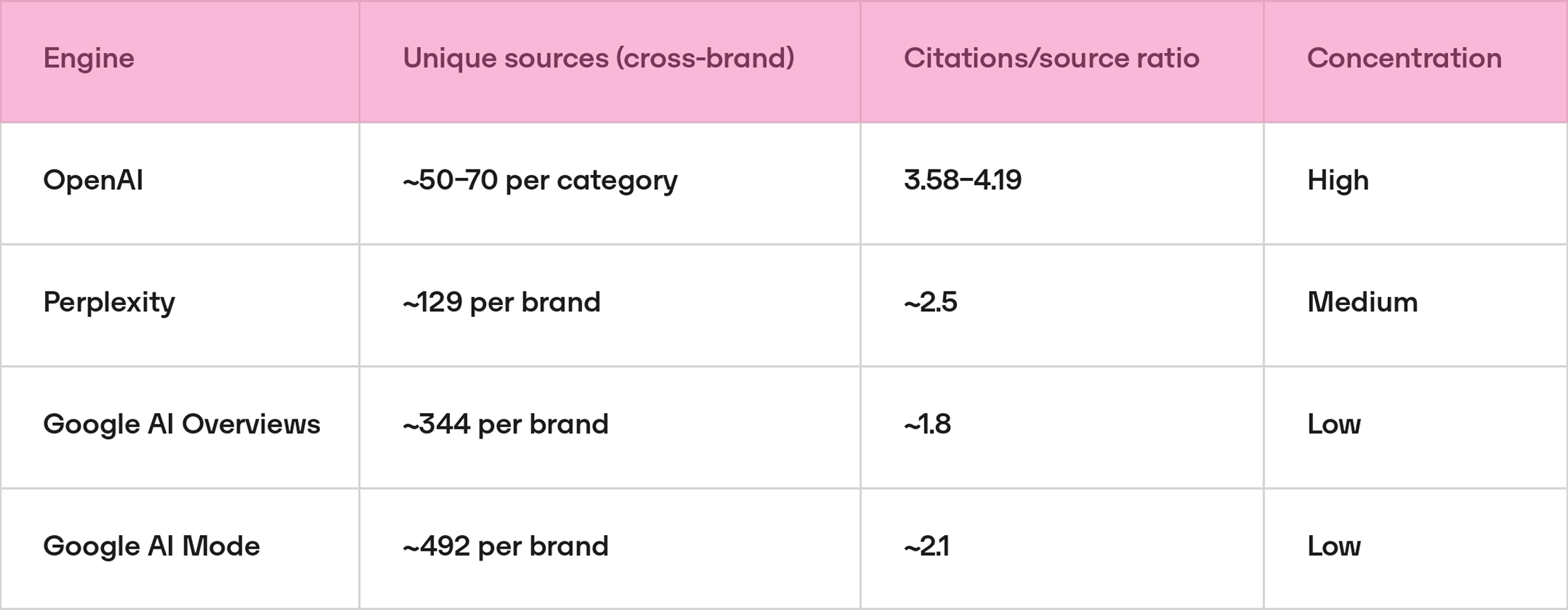
Pattern 5: Source concentration. OpenAI cites fewer domains but more frequently
OpenAI uses a significantly smaller source pool than other engines, but cites each source with greater repetition. This creates a high entry barrier: being among the reference domains determines visibility, not breadth of web presence.
Evidence:
- ChatGPT draws from the smallest source pool (roughly 50–70 unique domains per category) and cites each one an average of 3.5 to 4 times. Citation behaviour is highly repetitive and concentrated on a fixed set of sources.
- Perplexity operates at medium concentration, with around 129 unique sources per brand and a repetition ratio of ~2.5. Its retrieval is broader than ChatGPT's but still shows meaningful source reuse.
- Google AI Overviews and Google AI Mode show the lowest concentration, pulling from 344–492 unique domains per brand and citing each source approximately once. The distribution of citations is markedly flatter than in the other two engines.
Mechanism: ChatGPT does not perform RAG (real-time retrieval) in the same way as Perplexity or Google AI Mode. Its responses are generated largely from patterns learned during training, which concentrates references on a set of sources the model "remembers" most frequently.
Brand implication: To appear in ChatGPT it is more effective to gain presence in 5–10 high-authority domains than to be mentioned diffusely across hundreds of sites. Content strategy should prioritise source quality over mention volume.
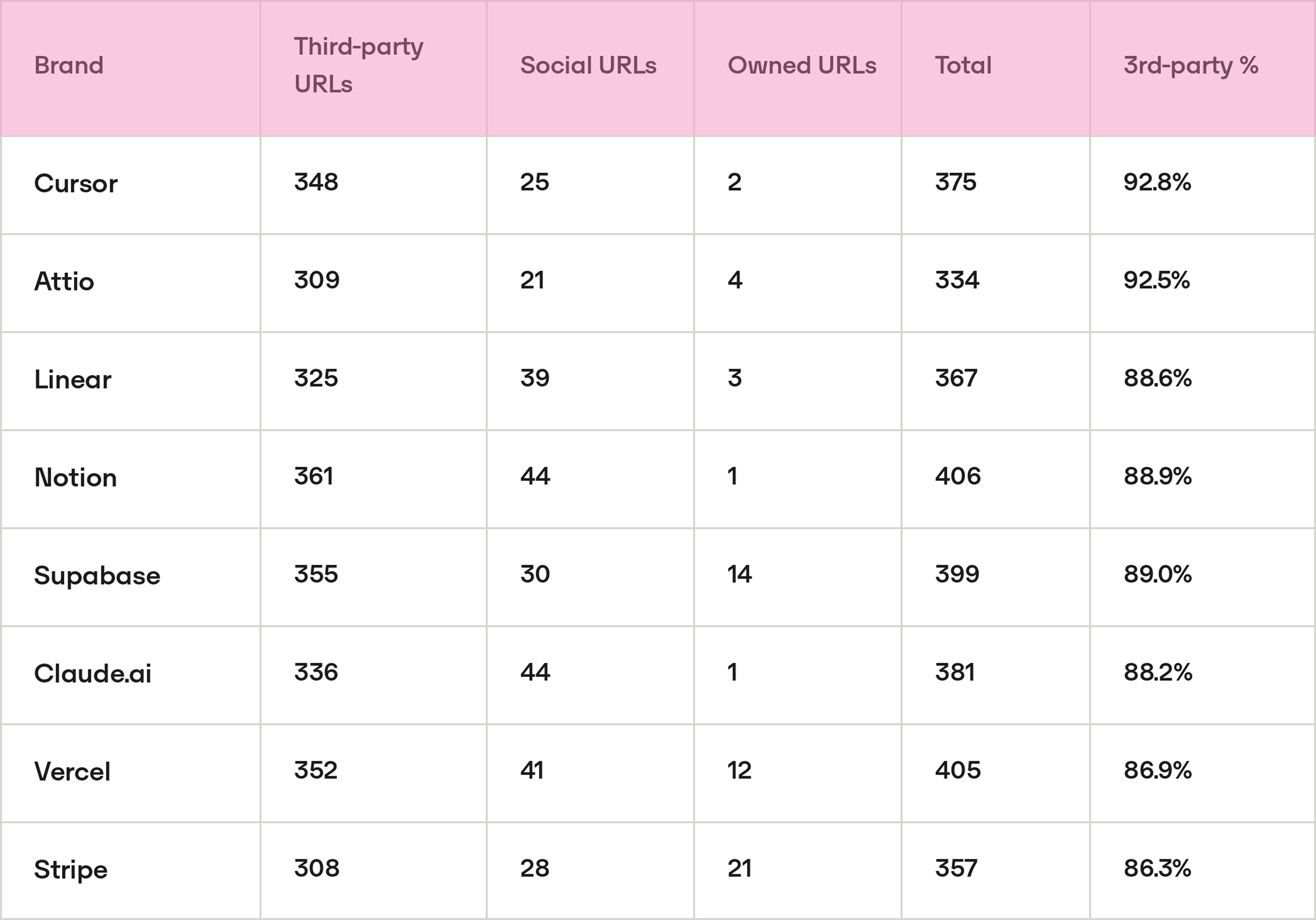
Pattern 6: ChatGPT's citation pool is ~89% third-party content
Across all 8 brands, the source type breakdown in ChatGPT is almost structurally identical: approximately 89% third-party, 9% social (Wikipedia, Reddit, LinkedIn), and under 2% owned. This ratio is consistent regardless of category, brand size, or SOV rank.
Within third-party content, a single archetype dominates across every category: comparison and "pros/cons" review articles. The most cited URLs per brand are almost exclusively from this template:
- Attio: "Salesforce Reviews, Pricing & Features 2026" (49 cit), "HubSpot CRM: Pros and Cons" (36 cit)
- Cursor: "Copilot vs Cursor vs Codeium: Which AI Coding Assistant Actually Wins in 2026?" (46 cit), "GitHub Copilot Pros and Cons" (43 cit)
- Vercel: "Fly.io Reviews 2026" (36 cit), "Fly.io vs Railway 2026" (32 cit)
- Stripe: "Paddle Review 2026: Pros, Cons & Pricing" (67 cit), "Paddle Review: Features, Pricing, Pros & Cons" (52 cit)
Evidence:
Note that in several cases the most cited third party articles are primarily about a competitor, with the studied brand appearing as a secondary reference. Stripe's top citation is a Paddle review. Vercel's top citation is a Fly.io review. This means brands can accumulate negative citation exposure, being mentioned as the inferior option in a competitor's review without having any control over the framing.
Mechanism: ChatGPT does not perform real-time retrieval. Its citation behaviour reflects what was indexed and weighted during training. Review and comparison content is heavily cross-linked by developer communities, aggregators, and newsletter roundups, which gives it disproportionate weight in a corpus trained on link-graph authority signals. The consistency of the 89% ratio across all 8 brands suggests this is a structural characteristic of ChatGPT's citation behaviour, not a category-specific artifact.
Brand implication: For ChatGPT visibility, the strategic content investment is earning presence in third-party comparison and review articles, not publishing brand content. The specific target archetype is "Best [category] tools" and "[Brand] vs [Competitor]" articles on established tech publications. Being absent from those articles or appearing only as the secondary option, directly limits ChatGPT citation share. The data also suggests monitoring competitor review content is as important as monitoring your own: if a competitor review article consistently frames your brand as the weaker choice, that framing is likely propagating into ChatGPT responses.
Conclusion
The six bias patterns documented in this report share a common root: ChatGPT's output reflects its training data, not only a live read of the market.
Some of these biases are architectural, such as the reliance on Wikipedia or the concentration of citations in a fixed source pool. Others are relational, stemming from OpenAI's commercial ties to Microsoft and GitHub. Others still are structural features of how web content was weighted during training. In all cases, the result is the same: the rankings ChatGPT produces are not a 100% neutral measure of current brand authority.
This has a direct methodological implication. For categories where ChatGPT has a conflict of interest, such as AI assistants or developer tooling adjacent to the Microsoft ecosystem, Perplexity and Google AI Mode produce less distorted benchmarks. Using ChatGPT as the primary visibility reference in those categories means interpreting results through a lens the data itself calls into question.

.png)



