


Tracking AI citations for your business means monitoring which sources AI engines pull when answering prompts in your category, by country, across ChatGPT, Perplexity, and Google AI Overviews. It is not the same as rank tracking. There is no position 1. There is cited or not cited, and the gap is diagnosable. The workflow: build a prompt bank of 15 to 25 intent-driven queries, run them on a set cadence, log cited domains and URLs in a tracking schema, compare your presence against competitors, and update the pages that are losing citations to the pages that are winning them. The key metric is citation frequency, not impressions. The key output is a prioritized fix-it list, not a dashboard. To know how to track AI citations for your business in a repeatable way, you need a system that runs weekly and feeds directly into content updates. Start this week: pick 5 high-intent prompts in your category, run them three times each in ChatGPT and Perplexity, and log which domains get cited.
Your organic traffic is down. ChatGPT is recommending someone in your category, but it is not you. You have looked at Google Analytics, Search Console, even a few SEO dashboards, and none of them explain what is happening or what to fix. That is not a data problem. It is a visibility layer problem, and most teams do not have the tools or the workflow to see it yet.
AI engines like ChatGPT, Perplexity, and Google AI Overviews do not rank pages. They cite sources. And the gap between "we publish content" and "AI engines actually reference us" comes down to a measurable, actionable system that most startups have not built yet. This guide gives you that system: how to audit where you stand today, why competitors get recommended and you do not, and how to close the gap without starting from scratch.
What is AI citation tracking for businesses? (and why your current analytics won't show it)
AI citation tracking is the practice of monitoring whether and how AI engines reference your brand, content, and URLs when generating answers to prompts in your category. When a user asks ChatGPT "what is the best GEO tool for B2B startups" or Perplexity "how do I improve my brand visibility in AI search," those engines pull from a set of sources to construct their answers. Citation tracking tells you which sources they are using, whether yours are among them, and what your competitors are doing differently when they are.
This matters because AI engines are increasingly where buying decisions start. A founder researching tools, a marketing lead benchmarking platforms, an SEO manager looking for a new workflow: they are asking AI assistants before they visit websites. If your content is not being cited in those answers, you are invisible at the moment intent is highest.
The pain point most teams run into is not a lack of data. It is the wrong data. Your current analytics stack was built for a deterministic web: a user clicks a link, a session fires, a source gets credited. AI answers do not work that way. There is no click to track when ChatGPT recommends your competitor. There is no impression logged when Perplexity cites a third-party domain that mentions them and not you. Google AI Overviews have begun to surface in GA4 and Search Console in limited ways, but the data is incomplete, inconsistently attributed, and tells you nothing about why a citation happened or what to change to earn one. Citation tracking fills that gap: it tells you what AI engines are actually doing with your content, and what to do next.
Citations vs mentions vs recommendations (use a simple rubric)
These three terms get used interchangeably, but they measure different things and require different responses. Here is a working rubric you can reuse in your reporting template:
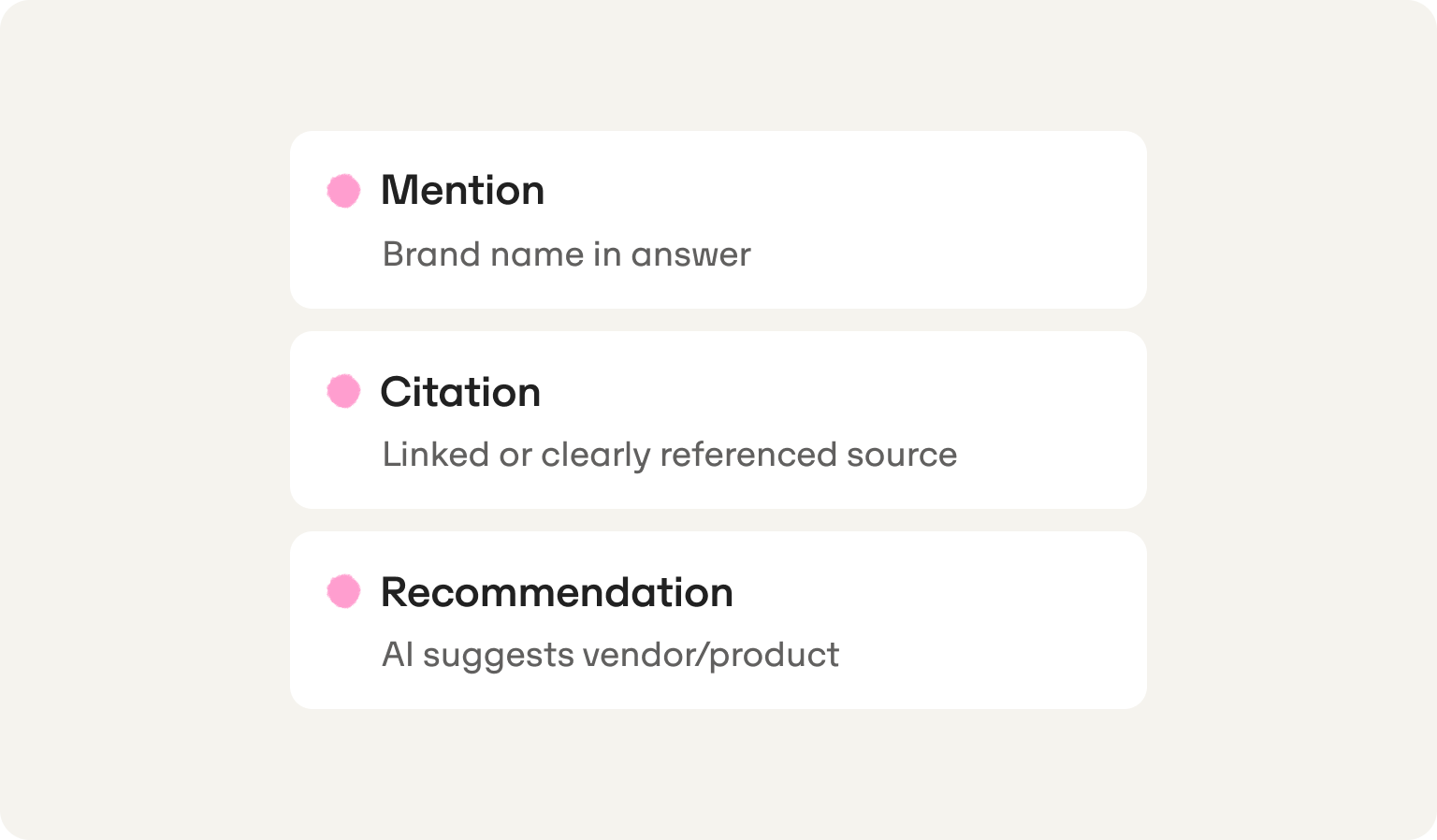
A mention without a citation means you have awareness but no source authority. A citation without a recommendation means AI trusts your content but is not yet routing buyers to you. The goal is to move from mention to citation to recommendation, prompt by prompt. When you run your tracking schema (covered in Step 4 below), log all three columns for every run so you can measure progress across all three dimensions, not just whether your name showed up.
How it differs from traditional SEO tracking (rankings, clicks, Search Console)
Traditional SEO tracking is deterministic. A page ranks at position 3 for a keyword, that position is consistent enough to report, and Search Console connects the dots between queries, impressions, and clicks. The whole system assumes predictability.
AI answers do not offer that. Ask ChatGPT the same question three times and you may get three different sets of cited sources. There is no canonical rank position, no impression logged when a competitor gets recommended, and no click to attribute when a buyer makes a decision based on an AI answer. Search Console has limited, inconsistent visibility into AI Overviews and none at all into ChatGPT or Perplexity.
This is why citation tracking runs on sampling and frequency rather than positions and clicks. It is a different reporting model for a different kind of visibility, and the sooner your team stops expecting GA4 to explain it, the sooner you can start measuring what actually matters.
How these ai citation tools work (and what data is actually being captured)
AI citation tracking tools send structured prompts to AI engines, record the answers, and extract the sources referenced in each one. Depending on the engine, that happens through direct API access or browser-level scraping for surfaces like Google AI Overviews. The prompt goes in, the answer comes out, and the cited domains and URLs get pulled, normalized, and logged.
What gets captured is a sample, not a census. No tool is reading every AI answer generated globally. The value is in running the same prompts, in the same conditions, on a consistent cadence, until the citation patterns become clear. A single run is a data point. A hundred runs across four weeks is a signal you can act on.
Engines to cover (don't pretend one engine = the market)
Your buyers are not using one AI engine. Treating ChatGPT as a proxy for all of AI search is the same mistake as tracking Google and ignoring Bing back when that still mattered. Today it matters more, because the citation logic is different across surfaces, the source pools overlap but do not match, and a competitor can dominate one engine while being invisible in another.
The three surfaces worth tracking for most B2B startups:
- ChatGPT: Citation behavior shifts depending on browsing settings, product version, and prompt phrasing. Sources are not always surfaced as clean linked references, so good tracking tools extract citations from answer text as well as the UI.
- Perplexity: Citation-forward by design. Sources are explicit, consistent, and easier to extract than on other surfaces. It is one of the most useful engines for diagnosing why a competitor is trusted and you are not.
- Google AI Overviews: A SERP feature, not a standalone assistant. It appears selectively, pulls sources that often diverge from the top organic results for the same query, and tends to be more volatile than the other two. Worth tracking, but interpret the data with that context in mind.
Country and localization: how to avoid mixing global noise with local reality
The sources ChatGPT cites for "best GEO tool for startups" in the UK are not the same ones it cites in Spain. Competitor sets differ. Source authority varies by market. The content pool AI engines draw from reflects local publishing ecosystems, and blending results across geographies does not give you a global view. It gives you a blurred one that is harder to act on.
Lock in your tracking controls before you run a single prompt:
- Country and language setting
- Logged-in vs logged-out state
- Exact prompt text, not paraphrased variations
- Device type if tracking Google AI Overviews
If your priority markets are Spain and the UK, run them as two separate prompt sets with separate reporting. A citation win in London tells you nothing about Madrid. Keep them clean.
How to implement AI citation monitoring for brand visibility optimization (the repeatable workflow)
This is the part most guides skip. They tell you citations matter, show you a dashboard screenshot, and leave you to figure out the rest. What follows is a workflow a lean team can actually run weekly, with concrete defaults you can copy and adjust as your data matures.

Step 1: Build your prompt bank (15–25 prompts that you know will actually drive intent)
Your prompt bank is the foundation of everything. Bad prompts produce noise. Prompts that mirror how real buyers actually talk to AI engines produce signal.
A strong prompt bank covers six categories:
- Category prompts: "Best [your category] tool for [use case]"
- Problem prompts: "How do I [problem your product solves]"
- Comparison prompts: "[Your brand] vs [competitor]"
- Alternatives prompts: "Alternatives to [competitor]"
- Integration prompts: "[Your category] that integrates with [common tool in your stack]"
- Pricing prompts: "How much does [your category] cost"
Include competitor names in a subset of your prompts. Buyers use them, and AI engines respond to them. Ignoring that means missing a category of answers where your competitors are actively being recommended and you are not.
Example prompts for a B2B SaaS startup (swap placeholders for your category and market):
- "Best [your category] tools for startups in [country]"
- "How do I improve my brand visibility in AI search"
- "What is [your category] and how does it work"
- "How do [your category] tools track AI citations"
- "[Your brand] vs [competitor A]: which is better"
- "Alternatives to [competitor B] for early-stage startups"
- "Best [your category] tool for a team of one or two marketers"
- "How do I know if my content is being cited by ChatGPT"
- "[Your category] tools that integrate with [CMS or common stack tool]"
- "How much does [your category] software cost in [country]"
- "What should I look for in a [your category] platform"
- "How do I get recommended in AI search without a big content team"
You don’t need to have a massive amount of prompts. 15. Add prompts as you identify gaps. Keep the list stable enough to track trends over time; changing prompts mid-cycle resets your baseline.
Step 2: Pick competitors and entities to track (so you can explain "why them, not us")
Citation tracking only becomes diagnostic when you know who you are being compared against. Pick three to six direct competitors and track them consistently across every prompt run. If your category is new and competitors are fuzzy, track the domains that keep appearing in answers to your category prompts, even if they are not direct product competitors. Publishers, review sites, and thought leaders often show up as cited sources before branded tools do.
Beyond competitors, identify five to ten entities that regularly appear in AI answers in your space. These are not brands; they are concepts, standards, use cases, integrations, and tools that AI engines treat as relevant context when answering questions in your category. For a GEO or AI visibility tool, those entities might include things like prompt engineering, LLM training data, structured content, AI Overviews, or specific CMS platforms. Tracking entity coverage tells you whether AI engines associate your brand with the right concepts, not just whether your name shows up.
Step 3: Decide your routine and sampling (because AI answers are probabilistic)
One run per prompt is not enough. AI answers vary across runs, so a single result tells you almost nothing about citation reliability. The goal is to run each prompt enough times to see a consistent pattern, without burning your team's time on diminishing returns.
A practical baseline you can follow without getting overworked:
When runs disagree, use a majority rule: if your domain appears in 3 out of 5 runs, count it as cited for that cycle. If it appears in 1 out of 5, flag it as low-confidence and increase runs before drawing conclusions. The point is not to chase perfect data. It is to build a consistent enough picture that you can tell the difference between a real citation gap and random variation.
Step 4: Capture outputs in a tracking schema (sheets-friendly)
Before you have a dedicated tool, consider seeing citations with your own prompt research. A well-structured spreadsheet can do the job. Here is a column schema you can copy directly:
One de-duplication rule worth enforcing from day one: normalize all URLs before logging. Strip UTM parameters, trailing slashes, and query strings. Treat useomnia.com/blog/geo-tool and useomnia.com/blog/geo-tool?utm_source=twitter as the same URL. Without this, your cited URL counts become unreliable fast.
Step 5: Turn data into actions (the weekly fix-it loop)
Data without a loop attached to it is just a dashboard. Here is the five-step sequence that turns your tracking schema into actual visibility gains:
- Find the gap: Identify prompts where a competitor is cited and you are not. These are your highest-priority targets.
- Diagnose the citation: Look at which specific page or domain the competitor is getting cited for. Is it a blog post, a docs page, a comparison page, a third-party review? The page type tells you what kind of content AI engines trust for that prompt.
- Map to your closest existing page: Before creating anything new, find the page on your site that is most relevant to that prompt. In most cases, the fix is an update, not a new piece of content.
- Update for citation-readiness: Improve structure, add missing entities, sharpen the definition block, tighten the evidence, and add internal links to your source-of-truth pages. The on-page patterns section below covers exactly what to change.
- Re-monitor to confirm regained inclusion: Run the same prompt set the following week. If your updated page starts appearing in citations, log the win and move to the next gap. If it does not, go deeper on the diagnosis before making more changes.
This loop does not require a large team or a large budget. It requires consistency. Run it weekly, keep the schema clean, and the compounding effect on your citation presence becomes visible within a few cycles.
How to measure citation frequency in conversational AI (metrics that don't lie to you)
Good metrics tell you what to do next. Bad metrics make you feel busy. The KPIs below are designed to be calculated from your tracking schema without a data science degree, and honest enough that you can present them to leadership without having to caveat everything.
Core KPIs (with simple formulas you can understand)
How to explain AI citations volatility to your boss
AI citation data moves. A metric that was 60% last week might be 40% this week, not because anything changed on your site, but because AI engines updated their source preferences, the prompt triggered a different answer pattern, or sampling variance caught you on a bad run. If you report raw weekly numbers without context, you will spend half your stakeholder meetings defending fluctuations instead of discussing actions.
A simple volatility score helps: track the week-over-week change in citation frequency for each prompt and flag anything that moves more than 20 percentage points in either direction as a volatility event worth investigating before acting on. For high-value prompts, increase your runs to five or more per cycle to tighten your confidence band.
When something moves and you need to explain it, here is something you could write (or say) to provide any stakeholder update:
"Citation frequency for [prompt] dropped from [X%] to [Y%] this week. Before drawing conclusions, we are running an additional two cycles to confirm whether this is a real shift or sampling variance. If it holds, the most likely cause is [competitor update / source pool change / content freshness issue], and our planned response is [specific action]. We will have a clearer picture by [date]."
Calm, specific, and it does not overclaim. That is the standard to hold yourself to when reporting probabilistic data to people who are used to deterministic metrics.
How to track AI citations for your content (page-level and cluster-level tracking)
Knowing your brand is being cited is a start. Knowing which specific page got cited, and why, is where the work actually begins. This is the layer that turns "we have a citation gap" into "here is the exact page we need to fix and here is what to change on it."
Page-level: map citations to the exact URL and page type
When a citation appears in your tracking schema, the first question is not "did we win?" It is "which page won, and what type is it?" Page type tells you what AI engines trust for different kinds of prompts, and that tells you where to focus your updates.
Tag every cited URL by page type as you log it:
If a competitor's blog post is getting cited for a prompt where you have a landing page, that is diagnostic. AI engines are reaching for an explanatory source and finding yours unconvincing. The fix is usually not a new page. It is restructuring what you already have to look more like the kind of source that gets cited.
Topic cluster-level: find which themes AI trusts you on (and ignores)
Page-level tracking tells you what is happening. Cluster-level tracking tells you why, and where to put your energy next.
Group your tracked prompts into five to eight topic buckets and score your citation frequency within each one. A lean team does not have the bandwidth to fix everything at once. Cluster scoring tells you exactly where to start.
Suggested buckets for a B2B SaaS startup:
- Use cases — prompts about specific problems your product solves
- Integrations — prompts about your category plus specific tools or platforms
- Pricing — prompts about cost, value, and comparison
- Implementation — prompts about setup, onboarding, and getting started
- Alternatives — prompts about competitors and switching
- Security and compliance — prompts about trust, data handling, and standards
- Category education — prompts about what your category is and how it works
Once you have scored each cluster, prioritize the ones where two conditions are true at the same time: competitor citation density is high and your own citation frequency is low. That combination means buyer intent is real, AI engines are already routing it somewhere, and that somewhere is not you. Those are the gaps worth closing first, and they are almost always fixable with existing content rather than net-new pages.
For startups optimizing content to influence LLM answers, cluster-level tracking is the difference between a scattered content calendar and a focused one. It tells you which themes to double down on and which ones to deprioritize until the high-intent gaps are closed.
How to track AI citations for your business content (ownership, distribution, and off-site citations)
Not every citation that matters points to your website. AI engines pull from across the web, and some of the most authoritative sources in your category are third-party: review platforms, industry publications, founder posts, partner pages, community threads. Tracking only your owned URLs means missing a significant share of the citation landscape and leaving distribution levers unused.
The non-owned column is where most lean teams leave value on the table. If Perplexity keeps citing a specific industry publication for prompts in your category and you have never contributed to it, that is not bad luck. It is an unworked distribution channel. The same logic applies to community platforms, integration directories, and partner pages. These are not content marketing nice-to-haves. They are citation sources that AI engines have already decided to trust.
Owned vs non-owned: what you can control directly
When a citation appears in your tracking schema, the first thing to establish is whether you own the source or not. The action that follows depends entirely on that answer.
If the citation points to your site, you have direct control. A page that is already getting cited needs to be protected: keep it fresh, strengthen its internal links, and monitor it for regression. A page that exists but is not getting cited needs to be updated. Structure, entities, evidence, and freshness are usually the culprits, and the refresh checklist below covers exactly what to fix.
If the citation points somewhere else, your job is distribution. When a third-party source is being cited for a prompt in your category, that domain has already earned AI engine trust. The question is whether your brand, data, or perspective is on it. If it is not, that is an unworked channel, not bad luck. Industry publications, integration directories, community platforms, and partner pages all fall into this bucket. Getting placed on the right ones is not a nice-to-have content play. It is a direct lever on which sources AI engines reach for when a buyer asks a question you should be answering.
The non-owned column is where most lean teams leave the most value on the table. Your owned pages are one part of the picture. The sources AI engines have already decided to trust are the other part, and working both sides is what separates a citation strategy from a content calendar.
Brand safety: when citations are wrong, outdated, or negative
Not every citation is a win. AI engines sometimes pull from outdated pages, deprecated product documentation, or third-party sources that contain incorrect information about your brand. Left unaddressed, these citations actively work against you: a buyer asks ChatGPT about your pricing and gets a number that is two years old, or asks about your integrations and gets a list that no longer reflects your product.
Run this checklist any time a flagged citation appears in your tracking schema:
- Is the cited page still accurate? Check pricing, features, positioning, and any specific claims
- Is the cited page yours or a third party's? If third-party, can you update the source or publish a more authoritative alternative?
- Is the sentiment neutral or negative? If negative, identify whether the underlying claim is factual or disputable
- Is there a more current page on your own site that should be ranking instead?
The fix in most cases is straightforward: update your source-of-truth pages, consolidate outdated content, and re-monitor the affected prompts the following week to confirm the citation has shifted. What you want to avoid is letting bad citations compound. AI engines form habits, and the longer an incorrect source stays cited, the harder it becomes to displace.
How to optimize blog content for AI citation (on-page patterns that get cited)
Rankings and citations are not the same thing. A post can sit at position two in Google and never appear in a single AI answer. AI engines are not looking for the most authoritative domain. They are looking for the clearest, most extractable answer to a specific question. That is good news for lean teams: you do not need more content, more backlinks, or a bigger brand. You need better structure.
The on-page patterns that get cited consistently come down to three things: a definition block in the first 100 words, a TL;DR up top, and at least one structured element like a table or Q&A section that AI engines can extract without needing to interpret the surrounding context. Among many content best practices at Omnia, we always make sure to provide our readers (and LLMs) with TL;DR and FAQ that are really on their minds.
Beyond that, the technical and structural changes worth prioritizing are well documented, and the refresh checklist in the next section gives you a copy-paste action list to work through on any underperforming page.
One test worth running before you touch anything: read any paragraph in isolation and ask whether it answers a specific question completely. If it only makes sense in context, it is not citation-ready.
Which strategies to apply to improve AI citation rates without new content

The instinct when citation rates are low is to publish more. Resist it. The relationship between publishing volume and being found has broken down. Two years ago, consistent output correlated with visibility. That logic no longer holds for AI search. One Omnia customer, OkTicket, saw a 30% increase in AI-driven inbound leads — not from flooding their blog, but from fixing the structure and specificity of content they already had.
For a small team, that is genuinely good news: you do not need to publish at scale. You need to publish with intent. Pick the 10 to 15 queries that matter most to your buyers, build one authoritative piece per query, and make sure each has a clear definition, specific numbers, and a structure AI can extract from. The constraint is not output. It is knowing what to create and where. In most cases, the content already exists. It just is not structured, distributed, or connected in a way that AI engines can act on.
The 10-point refresh checklist (copy and paste)

Run this checklist on any post that is missing from AI citations but should be there. Work through it in order: the first five changes tend to produce the fastest citation gains.
- Add or rewrite the definition block in the first 100 words
- Add a TL;DR immediately after the intro
- Update all statistics and link to primary sources
- Rewrite headings to match the language of your tracked prompts
- Add a Q&A section with three to six questions framed as buyers would ask them
- Add at least one table: a comparison, a checklist, or a step sequence
- Consolidate any thin sections under 100 words that do not answer a specific question
- Add internal links from your highest-authority pages to this post
- Fix any sections that use vague or hedged language and replace with conditional, specific claims
- Add a "last updated" note and a short limitations or caveats section to increase trust signal
A post that gets all ten updates is not just more likely to be cited. It is a better piece of content, full stop.
Content consolidation: when merging pages increases citation likelihood
Two posts covering the same topic at similar depth do not add up to twice the citation authority. They split it. AI engines pick one and ignore the other, and the one they pick is usually not the one you would choose.
The decision rule is simple: if two pages target overlapping intents and neither is being cited consistently, merge them. Take the stronger structural elements from each, redirect the weaker URL to the consolidated page, and update internal links across the site to point to the new version.
Merge when you see two posts answering the same core question, a blog post and a landing page competing for the same prompt, or a cluster of short posts that individually lack the depth to be cited but together would cover the topic authoritatively. Do not merge pages with genuinely different intents just because they share a keyword. The goal is concentrated authority, not fewer pages for its own sake.
Distribution without publishing net-new URLs (where citations often come from)
Some of the most cited sources in any category are not blog posts. They are the places buyers and practitioners already go to research decisions. Getting your brand and perspective onto those surfaces is often faster and more impactful than publishing a new post and waiting for AI engines to find it.
Six distribution plays worth running before you write a single new page:
- Update your integration and partner pages. If tools in your category are mentioned in AI answers, your presence on their ecosystem pages is a direct citation lever.
- Publish community Q&A responses. Thoughtful, specific answers on platforms like Reddit or niche Slack communities regularly get cited by Perplexity and ChatGPT. Write them like mini blog posts, not chat messages.
- Contribute founder or expert POV pieces to credible publications. A byline on a domain AI engines already trust is worth more than ten posts on a domain they have never cited.
- Complete and update directory and profile pages. G2, Capterra, and category-specific directories are frequently cited for comparison and alternatives prompts. Treat them as content, not admin.
- Pitch expert quotes to journalists and industry writers. A named quote in a cited article transfers authority to your brand even when your own site is not the cited source.
- Audit your existing guest posts and external mentions. Old placements that are outdated or inaccurate can be refreshed. New ones can be pursued on the same domains.
Track which of these placements start appearing as cited sources in your prompt runs. The ones that do are your highest-value distribution channels. Double down on them before looking elsewhere.
Why Omnia is the right fit for startups optimizing content to influence LLM answers

Most startups realize they have an AI visibility problem when a prospect says they had never heard of them, even after asking an AI about the category. By then, larger players have accumulated citations, been referenced in third-party roundups, and built enough presence that closing the gap takes real time. TUIO, an insurtech startup in Spain, went from 8.55% to 11.79% global share of voice in a matter of weeks, surpassing Mapfre and Santalucía — not through luck, but by knowing their gap and fixing it systematically.
Most AI visibility tools were built for enterprise teams with dedicated analysts, quarterly reporting cycles, and the bandwidth to interpret dashboards and translate them into briefs. That is not the reality for most startups. The reality is a marketing team of one or two people, a content calendar that is already stretched, and a founder who wants to know what is working and what to fix before the next board meeting.
Omnia is built for that reality. It tracks citation presence by country across ChatGPT, Perplexity, and Google AI Overviews, surfaces the exact domains and URLs competitors are getting cited for, and shows you the prompt-level gaps worth closing first. There is no ambiguity about what to do next. The data points directly to the pages that need updating and the distribution channels worth pursuing, so your team spends time executing instead of interpreting.
The three questions startups need answered are: where do we stand today by market, why are competitors getting cited and we are not, and what specifically should we change. Omnia answers all three in one place, with enough localization granularity to tell the difference between a citation gap in London and one in Madrid, and enough competitive intelligence to explain not just that a gap exists but what is driving it.
For a lean team trying to win a category narrative before larger competitors catch on, speed of diagnosis matters as much as quality of execution. The workflow this guide lays out, from prompt bank to tracking schema to weekly fix-it loop, is the one Omnia is designed to run and accelerate. Consider getting ahead with a free report with our AI rank visibility tracker or start for free and sign up for an Omnia account to run your first prompt audit with citation-level data rather than guesswork.
FAQs
How to track AI citations for your business for free?
You can build a basic citation tracking system without any paid tools. Pick ten to fifteen prompts from your category, run each one three to five times in ChatGPT and Perplexity, and log the cited domains and URLs in a spreadsheet using the schema outlined above. It is time-intensive and does not scale beyond a small prompt set, but it gives you a real baseline. The honest limitation is consistency: manual tracking is only as reliable as the discipline behind it, and without automation, cadence tends to slip as soon as the team gets busy. If not, there are other opportunities like obtaining a free report with Omnia’s AI visibility tracker.
What is a "good" AI citation rate for my industry?
There is no universal benchmark, and anyone quoting one is working with too little data to be credible. The more useful number is your citation rate relative to your tracked competitors, using the same prompt set, country settings, and sampling model. If your top competitor has 60% citation frequency across your shared prompt bank and you are at 20%, that gap is your benchmark. Close it prompt by prompt and the absolute number takes care of itself.
How to measure citation frequency in conversational AI without getting fooled by randomness?
Run each prompt at least three times per cycle, use a majority rule for reporting, and resist drawing conclusions from a single week of data. The metric to watch is directional movement over three to four cycles, not the raw number week to week. If your citation frequency for a high-value prompt moves from 20% to 60% over a month following a content update, that is a real signal. A single-week swing of similar size probably is not.
How do I know why a competitor is cited and I am not?
Start with the cited page itself. Look at the page type, the structure, how early the definition appears, whether there is a table or Q&A section, how recently it was updated, and what third-party domains link to or reference it. Then compare it honestly against your closest equivalent page. In most cases, the gap comes down to one of five things: structure, freshness, entity coverage, source authority of the citing domain, or distribution footprint. The AI citation analysis tools that surface cited URLs and domains make this diagnosis significantly faster than doing it manually.
How to optimize blog content for AI citation if my posts already rank in Google?
A Google ranking is not a citation guarantee. AI engines do not replicate SERP logic; they extract from sources they find clear and trustworthy, regardless of organic position. If a post ranks well but is not getting cited, the most common fixes are: add a TL;DR and definition block, rewrite hedged or vague sections with specific conditional claims, add a table, and tighten the Q&A to mirror real buyer prompts. Most well-ranking posts need a structural retrofit, not a rewrite.
What should I track by country vs globally?
Segment by country anything that varies by market: prompt outcomes, cited domains, competitor presence, and citation frequency. These differ enough across geographies that blending them produces data you cannot act on. Keep global your site architecture, canonical structure, schema markup, and source-of-truth pages. Those are consistent inputs; the citation outputs they produce will vary by market, and that variation is exactly what your country-level tracking is designed to capture.
Are "AI SEO" blogs trustworthy sources for building a citation strategy?
Useful for ideas, unreliable as ground truth. The space is moving fast enough that posts published six months ago may already reflect outdated engine behavior. Use them to generate hypotheses, then validate those hypotheses against your own prompt bank data. Your tracking schema is the most reliable source of truth you have, because it reflects what AI engines are actually doing in your specific category, for your specific prompts, in your specific markets. No industry blog can replicate that.
What is the fastest way to improve AI citations without publishing new pages?
Run the ten-point refresh checklist on the three to five pages most relevant to your highest-priority prompt gaps. Focus first on adding a definition block, a TL;DR, and a Q&A section, since these three changes tend to produce the fastest citation gains. In parallel, identify one or two third-party domains that AI engines are already citing in your category and pursue a placement on each. Give it two weeks and re-run your prompt set. If the needle has not moved, go deeper on the diagnosis before changing direction.




