Most advice on ranking in Perplexity borrows Google SEO logic and applies it to a system that selects sources by different criteria — which is why following it produces no measurable change in citation position. Based on Omnia's citation database of 42M+ citations, two content levers move the needle in Perplexity more reliably than anything else: publishing review and comparison pages, which earn the best average citation position of any page type at 3.1, and concentrating content depth on a narrow topic cluster rather than spreading it broadly. This article builds the improvement framework around those levers, with every tactic traceable to a named data source.
Most "how to rank in Perplexity" advice is just traditional SEO with a Perplexity label on top. Publish more content. Build domain authority. Improve your E-E-A-T signals. The advice is not wrong in principle, but it presents issues in sequence and in specificity. Perplexity selects sources by different criteria than Google does, and a team applying generic best practice to a system they have not diagnosed will spend months producing content that does not move their citation position in either direction.
The window to establish that position is also narrowing. According to Omnia's citation database that tracks 42M+ citations across four AI engines, Perplexity averaged 11.8 domains per answer in November 2025. By April 2026, that figure had contracted to 7.5 — a 36% decline in available citation slots in five months. The brands currently embedded in Perplexity's source signal layer for their category queries are harder to displace with each passing month. Late entrants are not locked out, but the path requires more precision than it did six months ago.
This article is built around three concrete improvement levers — content type selection, topical depth, and freshness cadence, and each grounded in what Omnia's citation data shows actually drives citation position in Perplexity, not what general best practice suggests should. If your question is how to measure whether any of these actions are working, which queries you are being cited on, at what position, and where competitors are gaining ground, the companion article on tracking brand mentions and citations in Perplexity covers that system. This article covers what to do before you need to measure it.
Why SEO logic does not transfer to Perplexity
The assumption most teams carry into Perplexity optimization is that the content ranking well in Google will rank well in Perplexity too. Omnia's citation data makes that assumption hard to defend.

The cross-engine content divergence is not subtle. According to Omnia's citation database, YouTube is cited 193,000 times in Perplexity against 16,000 times in ChatGPT — a 12x difference. Wikipedia runs in the opposite direction entirely: 200,000 citations in ChatGPT against 5,000 in Perplexity.
A brand whose primary content vehicle is editorial or encyclopedic authority will perform well in ChatGPT and poorly in Perplexity. A brand whose content is video-led or blog-heavy will see the inverse. The engines are not interchangeable, and a single content strategy cannot optimize for both simultaneously without understanding where the preferences diverge. This is one of the most consistent findings from Omnia's GEO vs. SEO research: the signals that predict citation in one engine actively mislead optimization efforts in another.
The second assumption worth dropping is that domain authority is the primary lever for citation position in Perplexity. Two examples from Omnia's citation database illustrate the point cleanly. rankshift.ai — a niche GEO tooling site — holds an average citation position of 1.9 across 2,807 citations. ecomm.design — a niche ecommerce design resource — holds an average position of 1.6 across 3,917 citations. Neither competes on raw domain authority. Both compete on one thing: deep, specific content concentrated on a single vertical topic.
The pattern holds across every vertical in Omnia's dataset: topical concentration predicts citation position in Perplexity more reliably than domain authority does. That is the source trust signal Perplexity weights most heavily at the query-specific level — not E-E-A-T breadth across a general subject area, but demonstrated expertise on the exact topic the query is asking about.
For a VC-backed startup with a focused product and a lean content team, that is structurally good news. Perplexity rewards depth in a narrow vertical over breadth across many topics — which means 40 tightly scoped articles covering one topic thoroughly outperforms 400 broad articles covering everything loosely. A startup that knows its category well and covers it specifically has a more realistic path to positions 1 and 2 than a generalist publisher with ten times the content inventory.
Lever 1: Publish the content types Perplexity actually cites
Not all content formats earn equal citation presence in Perplexity, and the volume vs. position split in Omnia's data is the finding most teams miss.
Blog and article content earns the highest raw volume of Perplexity citations at 22.8% of all citations tracked. But review and comparison pages earn the best average citation position of any page type at 3.1 — outperforming blog content (3.5), how-to guides (3.6), product pages (3.7), and help and FAQ pages (4.2).
The practical implication for a lean team is not to abandon blog content — 22.8% citation share is not a number to walk away from. It is to recognize that a single well-structured review or comparison page targeting a query where a competitor currently holds position three can outperform ten blog posts in citation position terms. The same Omnia dataset shows review and comparison pages also earn 10.1% of ChatGPT citations vs. blog content's 14.4% in ChatGPT, a narrower gap than in Perplexity, which makes review and comparison pages the closest thing to a cross-engine format that Omnia's data currently supports.
The question to apply to an existing content inventory before creating anything new: which pages are closest to a review or comparison format already, and what would it take to push them to that structure? AI-ready content built around direct, query-specific answers with explicit comparisons, named alternatives, and a clear verdict, is structurally what Perplexity is selecting for at position 3.1 and above.
Lever 2: Build topical depth, not domain breadth
The niche authority data from the previous section points directly to this lever. ecomm.design at position 1.6 and rankshift.ai at position 1.9 are not winning because they have more content than their competitors. They are winning because the content they have is concentrated on one topic cluster, covers it from multiple angles, and answers the specific queries Perplexity is receiving in that vertical.
For a VC-backed startup with a lean marketing team, the failure mode is spreading content across every topic that touches the product rather than going deep on the three to five topics that define the category. A brand that publishes ten articles on pricing strategy, eight on competitor comparisons, twelve on onboarding, and six on retention has not built topical authority in any of those areas. It has built a content library that Perplexity has no reason to treat as the definitive source on anything.
The approach that earns share of voice in Perplexity is the opposite: identify the one or two topic clusters where the brand has the deepest genuine expertise, map every query variant a buyer might run within those clusters across awareness, comparison, and validation intent, and build or restructure content to cover each variant specifically. Conversational content design — content structured around the exact question being asked rather than the broader topic — is the format that earns citation at positions 1 through 3 in Omnia's dataset, not content that gestures at a topic from a distance.
The audit question is simple: for the brand's core topic cluster, how many of the specific queries a buyer would run in Perplexity does the brand's existing content directly answer? Not cover generally — answer specifically, with a page structured around that exact query. The gap between the number of relevant queries and the number of pages with a direct answer is the content depth deficit. Closing it is lever two.
Lever 3: Maintain freshness on a cadence Perplexity can detect
Of the three levers, this is the one with the least Omnia-specific data behind it and the most observable behavioral evidence. Perplexity is built as a real-time research engine — it indexes and surfaces recently updated content as part of its core product promise to users. That architectural reality has a direct implication for citation maintenance: a page that was citation-worthy at publication does not hold that position indefinitely if it is left untouched while competitors update theirs.
The instruction here is about sequencing rather than volume. Before creating new content, identify the three to five pages in the existing inventory that are closest to citation-worthy on high-intent queries — review or comparison format, topically concentrated, query-specific — and update them first. A page Perplexity has already indexed and previously cited has an established crawl relationship that a brand new page does not. An update that adds a new data point, refreshes a comparison table, or expands a section with a query variant not previously covered is faster to citation impact than starting from scratch with a new URL.
Where Omnia's data does bear on this lever indirectly: the declining source pool from 11.8 domains per answer in November 2025 to 7.5 in April 2026 means Perplexity is consolidating around sources it already trusts. Maintaining freshness on pages that are already in that trusted set is how a brand protects a citation position it has earned. Letting those pages go stale hands the slot to a competitor who is updating theirs. It is the logical consequence of a contracting citation budget applied to a system that weights recency. The content freshness and recency signals that Perplexity responds to are real. The specific magnitude of their effect is something Omnia's dataset will quantify as more longitudinal tracking data accumulates.
How Omnia identifies the gaps these levers need to close
The three levers above are executable for a lean team running them manually against a single brand and a small query set. The problem surfaces when the team tries to identify which specific gaps to close first — which content type is missing from which query cluster, which topic areas have no owned citation presence, and which pages are losing citation position to a competitor who updated their content last month. Gathering that picture manually requires querying Perplexity across the full topic cluster, recording what appears, mapping it against the brand's existing content inventory, and doing the same for three to five competitors. That is not a two-hour-per-week task. It is a full-time research project.
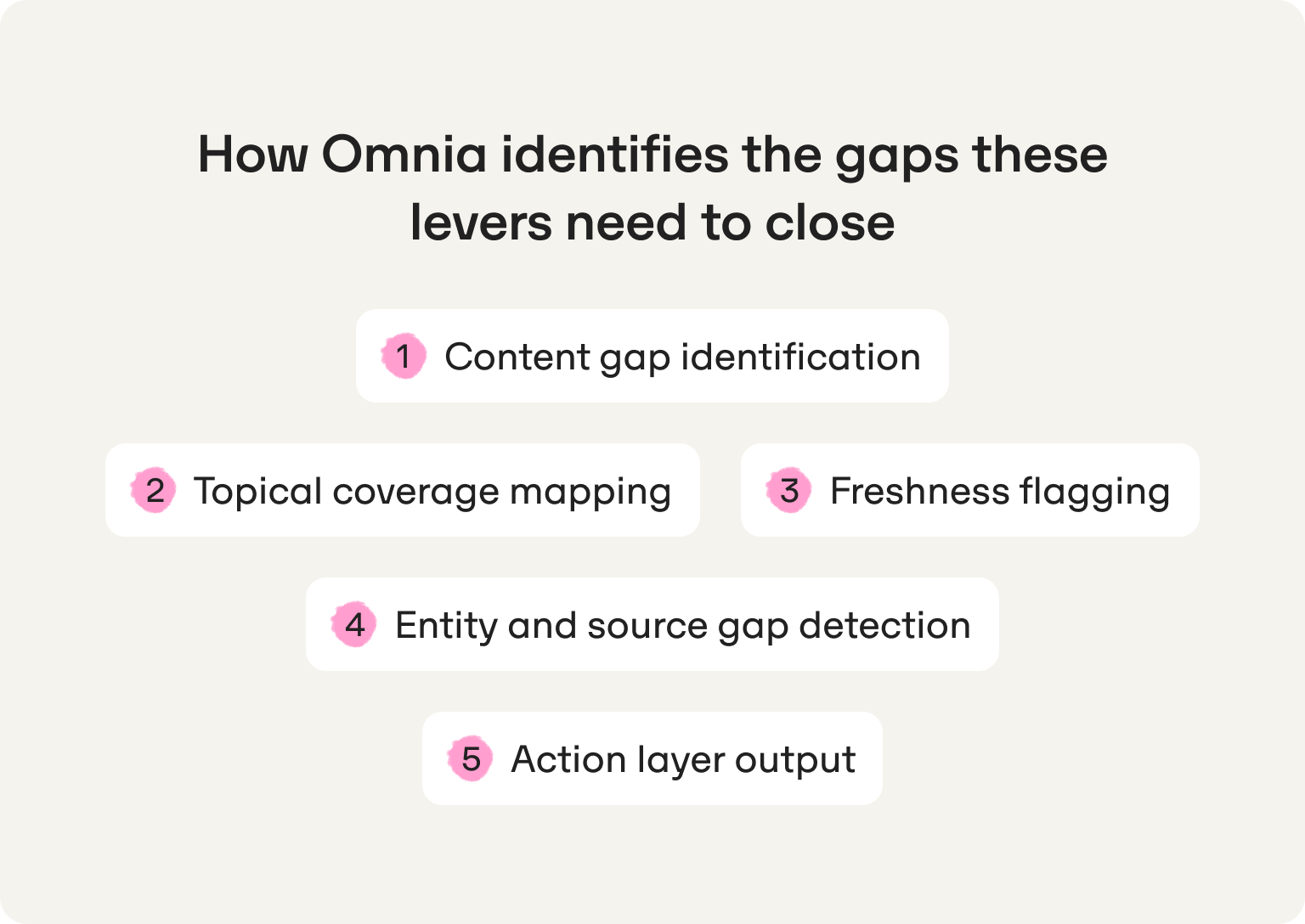
Omnia is built to close that diagnostic gap. Its specific capabilities for Perplexity visibility improvement:
- Content gap identification. Omnia identifies which content types Perplexity is currently citing for the brand's core query clusters — so the team knows whether the missing lever is a review page, a comparison page, or a how-to, rather than guessing and publishing into the dark.
- Topical coverage mapping. Omnia maps the brand's existing content against its citation gaps, surfacing which subtopics within the core vertical have no owned citation presence and which competitors are currently filling them.
- Freshness flagging. Omnia identifies which pages in the brand's inventory are losing citation position over time, so the team updates before the slot is lost rather than after a competitor has taken it.
- Entity and source gap detection. Omnia surfaces missing sources, entities, and content patterns that Perplexity is pulling from in the brand's category — the layer of intelligence that tells a team not just what to publish, but where to get cited before publishing anything new.
- Action layer output. Omnia's output is a prioritized content brief: a ranked list of what to publish, update, or place this week, with a specific rationale attached to each action. Not a visibility score to stare at. Not a dashboard to screenshot and share in Slack.
The agency partners running this system across client portfolios at scale are doing so because the manual version of the diagnostic above breaks down the moment a competitor set is added. A platform that runs the diagnosis continuously — and produces a brief rather than a report — is what makes the three levers above executable on a recurring basis rather than a one-time audit.
For a founder or head of marketing who needs to show citation movement to a board or CMO without adding headcount, the brief format matters as much as the data behind it. A ranked action list is a decision. A visibility dashboard is a document. Omnia produces the former.
See how Omnia identifies your Perplexity visibility gaps and book a demo with us.
FAQs
How long does it take to see improvement in Perplexity citation position after publishing new content?
Perplexity indexes and surfaces recently updated content faster than traditional search engines do, which means citation movement after a content action can appear within days rather than weeks. That said, no named data in Omnia's citation database currently quantifies a specific timeframe with enough consistency to state it as a rule. What the data does show is that pages already in Perplexity's trusted source layer — previously cited, regularly updated — respond to freshness changes faster than new pages entering the index for the first time. The fastest path to citation movement is updating an existing page that Perplexity has already cited, not publishing a new URL and waiting for it to be crawled.
Is it worth optimizing for Perplexity specifically, or should I focus on content that works across all AI engines?
The cross-engine content divergence in Omnia's citation data makes a single-strategy approach hard to defend. YouTube is cited 12x more in Perplexity than in ChatGPT. Wikipedia is cited 40x more in ChatGPT than in Perplexity. The engines have structurally different source preferences, and content optimized for one does not automatically perform in the other. The closest thing to a cross-engine format that Omnia's data supports is the review and comparison page — earning position 3.1 in Perplexity and 10.1% citation share in ChatGPT. If a lean team can only invest in one content format, that is where generative engine optimization efforts compound across the most engines simultaneously.
Does domain authority matter for ranking in Perplexity?
It is not irrelevant, but Omnia's citation data shows it is not the primary lever. ecomm.design holds an average citation position of 1.6 across 3,917 Perplexity citations. rankshift.ai holds 1.9 across 2,807. Neither is a high domain authority generalist publisher. Both are niche authority sites with deep, specific content concentrated on a single vertical. Topical depth predicts Perplexity citation position more reliably than domain authority does — which means a startup with 40 tightly scoped articles on one topic has a more realistic path to positions 1 and 2 than a generalist publisher with ten times the content inventory and a stronger backlink profile.
How is improving Perplexity visibility different from improving visibility in Google AI Overviews?
The source selection criteria are different enough that separate strategies are required. Google AI Overviews favor established domain authority and pull from a stable source field that has been roughly consistent since Q4 2025. Perplexity favors topical depth and content that directly answers the specific query being asked, with a source pool that has been contracting — down from 11.8 domains per answer in November 2025 to 7.5 in April 2026. The content that moves citation position in one engine does not reliably move it in the other, which is why tracking them separately matters as much as optimizing them separately.